Qwen2-VL的评测与学习
1. 背景
2024年是大模型的元年,每天都有大模型产生,怎么评价一个大模型的好坏需要设定一个标准。通过自己摸索的标准其实还是野路子。因此参考学习github上多模态大模型Qwen2-VL的评测,主要学习有2个方面,第一是学习多模态大模型参加了哪些评测,每个数据集分别是干嘛的。第二就是我们相关性的数据集的格式是什么样子的,怎么评测,从而建立自己的测试集。
Qwen2-VL的github链接:https://github.com/QwenLM/Qwen2-VL,最新的介绍如下:
- SoTA对各种分辨率和比例的图像的理解:Qwen2-VL在视觉理解基准上达到了最先进的性能,包括MathVista、DocVQA、RealWorldQA、MTVQA等。
- 理解 20min+ 视频:Qwen2-VL 具备在线推流功能,通过高质量的视频问答、对话、内容创作等方式,可以理解 20 分钟以上的视频。
- 可以操作您的手机、机器人等的代理:Qwen2-VL 具有复杂的推理和决策能力,可以与手机、机器人等设备集成,根据视觉环境和文本指令进行自动操作。
- 多语言支持:为了服务全球用户,除了英文和中文外,Qwen2-VL 现在还支持理解图像中不同语言的文本,包括大多数欧洲语言、日语、韩语、阿拉伯语、越南语等。
2. 测试数据集
2.1 图像基准测试
Image Benchmarks
| Benchmark | Previous SoTA (Open-source LVLM) |
Claude-3.5 Sonnet | GPT-4o | Qwen2-VL-72B (🤗 🤖 |
Qwen2-VL-7B (🤗 🤖) |
Qwen2-VL-2B (🤗🤖) |
|---|---|---|---|---|---|---|
| MMMUval | 58.3 | 68.3 | 69.1 | 64.5 | 54.1 | 41.1 |
| MMMU-Pro | 46.9 | 51.5 | 51.9 | 46.2 | 43.5 | 37.6 |
| DocVQAtest | 94.1 | 95.2 | 92.8 | 96.5 | 94.5 | 90.1 |
| InfoVQAtest | 82.0 | - | - | 84.5 | 76.5 | 65.5 |
| ChartQAtest | 88.4 | 90.8 | 85.7 | 88.3 | 83.0 | 73.5 |
| TextVQAval | 84.4 | - | - | 85.5 | 84.3 | 79.7 |
| OCRBench | 852 | 788 | 736 | 877 | 845 | 794 |
| MTVQA | 17.3 | 25.7 | 27.8 | 30.9 | 25.6 | 18.1 |
| VCRen easy | 84.67 | 63.85 | 91.55 | 91.93 | 89.70 | 81.45 |
| VCRzh easy | 22.09 | 1.0 | 14.87 | 65.37 | 59.94 | 46.16 |
| RealWorldQA | 72.2 | 60.1 | 75.4 | 77.8 | 70.1 | 62.9 |
| MMEsum | 2414.7 | 1920.0 | 2328.7 | 2482.7 | 2326.8 | 1872.0 |
| MMBench-ENtest | 86.5 | 79.7 | 83.4 | 86.5 | 83.0 | 74.9 |
| MMBench-CNtest | 86.3 | 80.7 | 82.1 | 86.6 | 80.5 | 73.5 |
| MMBench-V1.1test | 85.5 | 78.5 | 82.2 | 85.9 | 80.7 | 72.2 |
| MMT-Benchtest | 63.4 | - | 65.5 | 71.7 | 63.7 | 54.5 |
| MMStar | 67.1 | 62.2 | 63.9 | 68.3 | 60.7 | 48.0 |
| MMVetGPT-4-Turbo | 65.7 | 66.0 | 69.1 | 74.0 | 62.0 | 49.5 |
| HallBenchavg | 55.2 | 49.9 | 55.0 | 58.1 | 50.6 | 41.7 |
| MathVistatestmini | 67.5 | 67.7 | 63.8 | 70.5 | 58.2 | 43.0 |
| MathVision | 16.97 | - | 30.4 | 25.9 | 16.3 | 12.4 |
description
| 数据集 | 任务描述 | 任务类型 |
|---|---|---|
| MMMUval | 多模态综合理解与问答(Multimodal Understanding and QA),考察对多模态输入的综合理解能力。 | 多模态理解与问答 |
| MMMU-Pro | 高级多模态理解与问答,涉及更复杂的推理和知识调用能力。 | 多模态推理 |
| DocVQAtest | 文档视觉问答,基于文档图像的信息提取与问答。 | 文档视觉理解 |
| InfoVQAtest | 信息检索问答任务,结合视觉与文本,考察信息提取与回答的准确性。 | 信息检索与问答 |
| ChartQAtest | 图表问答任务,解析图表内容并回答相关问题。 | 图表理解与问答 |
| TextVQAval | 文字识别与视觉问答,主要测试模型对包含文字的图像内容的理解能力。 | OCR 与视觉问答 |
| OCRBench | 光学字符识别(OCR)任务,衡量模型提取图像中文字内容的准确性和效率。 | OCR |
| MTVQA | 视频多模态问答(Multimodal Temporal QA),结合时间轴上的多模态内容回答问题。 | 视频问答 |
| VCRen easy | 英文视觉常识推理(Visual Commonsense Reasoning, English),测试基于图像推理的能力。 | 常识推理 |
| VCRzh easy | 中文视觉常识推理(Visual Commonsense Reasoning, Chinese),针对中文场景的常识推理任务。 | 中文常识推理 |
| RealWorldQA | 真实世界问答,结合多模态信息回答现实问题,强调模型的实用性。 | 多模态问答 |
| MMBench-ENtest | 多模态基准测试,英文场景下的多任务评估。 | 多模态综合评估 |
| MMBench-CNtest | 多模态基准测试,中文场景下的多任务评估。 | 中文多模态评估 |
| MMBench-V1.1test | 更新版的多模态基准测试,包括更多任务和评估指标。 | 多模态综合评估 |
| MMT-Benchtest | 多模态翻译基准测试,考察模型在跨语言多模态任务上的性能。 | 多模态翻译 |
| MMStar | 多模态综合评估,覆盖视觉、文本、表格等不同模态的任务。 | 多模态综合评估 |
| MMVetGPT-4-Turbo | 专注于 GPT-4 等高级模型的多模态评估,考察新一代模型的综合表现。 | 多模态综合评估 |
| HallBenchavg | 综合任务基准,测试多模态模型的总体性能。 | 多模态综合评估 |
| MathVistatestmini | 数学与视觉任务,结合图像与数学问题解决能力。 | 数学与视觉任务 |
| MathVision | 视觉数学任务,强调通过视觉输入(如公式图像)解决数学问题的能力。 | 数学与视觉任务 |
其实我们比较感兴趣的是RealWorldQA,查看对应的数据集。
2.2 视频基准测试
Video Benchmarks
| Benchmark | Previous SoTA (Open-source LVLM) |
Gemini 1.5-Pro | GPT-4o | Qwen2-VL-72B (🤗 🤖) |
Qwen2-VL-7B (🤗 🤖) |
Qwen2-VL-2B (🤗🤖) |
|---|---|---|---|---|---|---|
| MVBench | 69.6 | - | - | 73.6 | 67.0 | 63.2 |
| PerceptionTesttest | 66.9 | - | - | 68.0 | 62.3 | 53.9 |
| EgoSchematest | 62.0 | 63.2 | 72.2 | 77.9 | 66.7 | 54.9 |
| Video-MME (wo/w subs) |
66.3/69.6 | 75.0/81.3 | 71.9/77.2 | 71.2/77.8 | 63.3/69.0 | 55.6/60.4 |
description
| 数据集 | 任务描述 | 任务类型 |
|---|---|---|
| MVBench | 多模态视频理解任务,测试模型对多模态视频内容的综合理解能力,包括文本和视觉信息的结合分析。 | 多模态视频理解 |
| PerceptionTesttest | 感知测试任务,评估模型对视觉场景的感知与分析能力,考察视觉认知的准确性和细节理解能力。 | 视觉感知与分析 |
| EgoSchematest | 自我场景推理任务,测试模型对自我中心视角(egocentric view)的场景推理能力,结合视频和空间理解。 | 自我视角推理与空间理解 |
| Video-MME (wo/w subs) | 视频多模态推理任务,分为有字幕和无字幕两种模式,评估模型在视频内容理解及多模态推理中的表现。 | 视频多模态推理 |
2.3 智能体评测
Agent Benchmarks
| Benchmark | Metric | Previous SoTA | GPT-4o | Qwen2-VL-72B | |
|---|---|---|---|---|---|
| General | FnCall[1] | TM | - | 90.2 | 93.1 |
| EM | - | 50.0 | 53.2 | ||
| Game | Number Line | SR | 89.4[2] | 91.5 | 100.0 |
| BlackJack | SR | 40.2[2] | 34.5 | 42.6 | |
| EZPoint | SR | 50.0[2] | 85.5 | 100.0 | |
| Point24 | SR | 2.6[2] | 3.0 | 4.5 | |
| Android | AITZ | TM | 83.0[3] | 70.0 | 89.6 |
| EM | 47.7[3] | 35.3 | 72.1 | ||
| AI2THOR | ALFREDvalid-unseen | SR | 67.7[4] | - | 67.8 |
| GC | 75.3[4] | - | 75.8 | ||
| VLN | R2Rvalid-unseen | SR | 79.0 | 43.7[5] | 51.7 |
| REVERIEvalid-unseen | SR | 61.0 | 31.6[5] | 31.0 |
description
| 数据集 | 任务描述 | 任务类型 |
|---|---|---|
| FnCall | 功能调用任务,评估模型处理函数调用或类似编程任务的能力(精确匹配 EM 和容错 TM)。 | 编程与函数调用 |
| Number Line | 数学任务,测试模型对数轴问题的解决能力,考察数学逻辑和推理。 | 数学推理 |
| BlackJack | 模拟游戏任务,评估模型在玩 BlackJack(21点)游戏中的策略推理和决策能力。 | 游戏策略与推理 |
| EZPoint | 数学任务,简单点数问题,考察模型的数学计算和逻辑推理能力。 | 数学计算与逻辑推理 |
| Point24 | 数学游戏任务,通过四则运算实现数字 24,测试模型的快速计算和逻辑能力。 | 数学游戏与推理 |
| AITZ | Android 模拟任务,评估模型在模拟 Android 环境下完成任务的能力(包括容错 TM 和精确匹配 EM)。 | 模拟环境任务(Android) |
| AI2THOR | 基于 AI2-THOR 环境的多模态任务,评估模型对未见场景的导航和任务完成能力。 | 环境导航与任务完成 |
| R2Rvalid-unseen | 室内导航任务,考察模型在未见房间中的导航能力(基于视觉和语言的导航任务)。 | 视觉导航与语言理解 |
| REVERIEvalid-unseen | 基于视觉的导航与推理任务,结合语言指令,完成未见场景中的复杂导航推理任务。 | 视觉导航与推理 |
3. 数据集案例参考
3.1 CMMMU
数据集介绍
CMMMU(Chinese Massive Multi-discipline Multimodal Understanding and Reasoning)是一个专为评估大型多模态模型(LMM)在中文环境下的理解和推理能力而设计的基准数据集。
**数据集特点:
- 多学科覆盖:CMMMU 涵盖了六大核心学科领域,包括艺术与设计、商业、科学、健康与医学、人文与社会科学、技术与工程,涉及超过 30 个细分学科。
- 多样化题目:数据集包含约 12,000 道多模态问题,这些问题主要来源于大学考试、测验和教材,确保了问题的专业性和多样性。
- 丰富的图像类型:题目中涉及 39 种不同类型的图像,如图表、示意图、地图、表格、乐谱和化学结构等,考察模型对多种视觉信息的理解能力。
- 中文背景:作为首个在中文背景下的多模态基准,CMMMU 专注于评估模型在中文语境中的表现,填补了该领域的空白。
数据集结构: - 题目数量:约 12,000 道题目,分为少样本开发集、验证集和测试集。
- 图像类型:包括病理图、乐谱、电路图、化学结构图等,共 39 种类型。
- 难度划分:根据逻辑难度,将题目分为简单(30%)、中等(58%)和困难(12%)三个级别。
CMMMU 可用于评估和比较不同大型多模态模型在中文多学科领域的理解和推理能力,为模型的改进和优化提供参考。
数据集学习
github下载网址:
1 | https://github.com/CMMMU-Benchmark/CMMMU.git |
查看目录可以看到:
1 | . |
其中cmmmu-data-dev,cmmmu-data-test, cmmmu-data-val都是测试数据集,可以看eval目录下的README.md,可以查看到使用方法,其中prompt在eval的configs下:
1 | task_instructions: |
根据README.md执行命令为:
1 | # eval_script.py是执行程序 |
打开cmmmu-data-val-answer.jsonl可以看到每个题目:
1 | {"id": 1900, "type": "选择", "source_type": "website", "source": "https://www.doc88.com/p-94761224603710.html", "question": "<img=\"q_01900_001.jpg\">为一幅灰度图,要为它局部添加颜色以得到右图所示的效果,正确的操作步骤是( )。", "option1": "先将色彩模式转为RGB,然后用工具箱中的 【画笔工具】上色", "option2": "先将色彩模式转为RGB,制作局部选区,然后打开【色相/饱和度】对话框,在其中点中【着色】项,调节色彩属性参数", "option3": "先将色彩模式转为RGB,制作局部选区,然后打开【可选颜色】对话框,调节参数", "option4": "打开【色相/饱和度】对话框,直接调节色彩属性参数", "answer": "B", "analysis": null, "distribution": "本科", "difficulty_level": "easy", "img_list": ["q_01900_001.jpg"], "subcategory": "设计", "category": "艺术与设计", "subfield": ["图像编辑", "色彩调整"], "img_type": ["屏幕截图"]} |
总结
CMMMU数据集的数据标注核心还是分类,通过让大模型爬取网页信息和图片,然后理解对应的图片和问题,每个问题都有单独的答案和问题分类。核心还是分类算法,最终以F1作为评价指标。
RealWordQA
网址:
1 | https://huggingface.co/datasets/lmms-lab/RealWorldQA |
数据集介绍
RealWordQA(有时也被写作 _RealWorldQA_)是一个面向真实场景的问答(Question Answering, QA)数据集,通常用于评测和研究在现实条件下自动问答系统的性能。与许多在实验室或小规模场景中构建的 QA 数据集不同,RealWordQA 的核心目标是让模型在多样化、噪声较多、数据来源复杂的真实环境中进行信息检索、阅读理解和答案推断,从而更好地反映模型在现实世界的使用效果。
数据来源与收集方式
1. 真实用户查询
- 部分题目直接来自搜索引擎、问答社区(如知乎、Quora 等)或社交媒体上的真实提问。
- 这些问题往往具有口语化、上下文缺失、带有一定噪声等特点,能更好地模拟真实用户的搜索或提问行为。
2. 多渠道文本语料
- 为了回答这些问题,数据集通常会提供来自网页、新闻、维基百科、社交平台、论坛等多种来源的文本片段,甚至包括音视频转写文本、图片描述等。
- 这些材料往往未经严格编辑,可能存在噪声、不完整或歧义,考验 QA 系统的鲁棒性和在非结构化文本中的检索能力。
3. 领域多样化
- 题目覆盖通用常识、专业领域(医学、法律、金融等)、科普类知识、社会热点、娱乐八卦等。
- 跨领域问题有助于检验系统在不同背景知识下的迁移能力。
数据标注与结构
1. 问答对 (Question-Answer Pairs)
- 数据集中通常包含大量问答对,每个问题对应一个或多个参考答案。
- 不同版本的数据集可能采用不同标注策略,如多段文本候选答案、单一文本答案、抽取式/生成式答案等。
2. 上下文文档 (Context/Passage)
- 每个问题附带至少一段与之相关的长文档或若干篇幅较短的文本片段,供模型检索或阅读理解。
- 在真实场景下,答案往往隐藏在文档中的某些片段,需要进行精确定位与抽取,或基于多处信息综合推断。
3. 质量控制 (Quality Control)
- 通常采用多轮人工过滤或审校来确保数据质量:问题是否清晰、答案是否正确或合理、上下文是否与问题相关。
- 由于数据规模大,仍会保留一定“真实噪声”,以便更好地模拟现实中的难度。
常见评测指标
- Precision / Recall / F1
- 用于衡量抽取式问答在文本中定位答案的准确性。
- EM(Exact Match)
- 答案字符串与参考答案的精确匹配度。
- BLEU / ROUGE / METEOR
- 主要用于衡量生成式答案与参考答案在字词层面或语义层面的相似度。
- A/B 测试
- 在真实系统中进行在线实验,观察用户点击率、停留时长、满意度等指标,也是一种评价方式。
数据集学习
数据集名字为:test-00001-of-00002.parquet,是parquet格式,使用pandas可以快速查看。
通过网页预览可以看到是真实图片加上问题再加上答案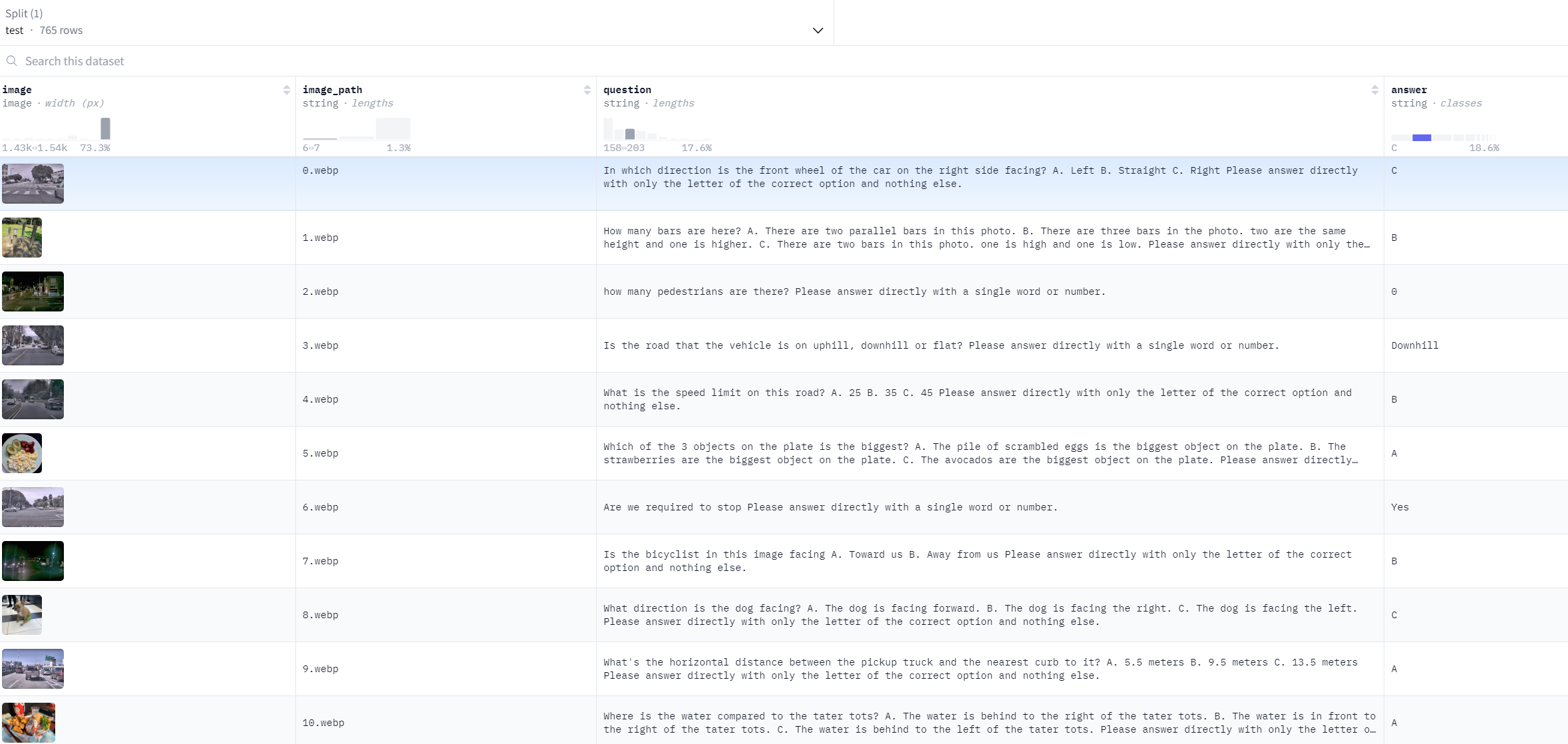
总结
数据集核心还是分类,通过提前分类测算F1值。







